
OpenAIのJason Wei氏のツイートの翻訳
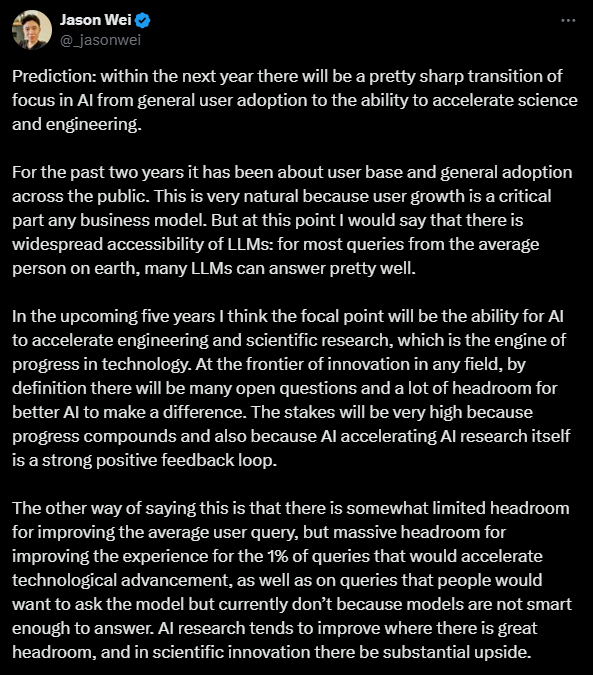
予測:今後1年以内に、AIの焦点は一般ユーザーの採用から、科学や工学を加速する能力へと急激に移行するだろう。
過去2年間、AIは主にユーザーベースの拡大や、一般社会への普及に注力してきた。この流れは非常に自然なもので、ユーザーベースの成長はどんなビジネスモデルにおいても重要な要素だからだ。しかし、現時点で言えるのは、LLM(大規模言語モデル)は広くアクセス可能となり、地球上のほとんどの人が抱える一般的な質問には、多くのLLMが十分に答えられる状況にあるということだ。
これからの約5年間、AIの焦点は、工学や科学研究を加速させる能力に移ると考えている。これらは技術の進歩を支えるエンジンだ。あらゆる分野の革新の最前線では、定義的に多くの未解決の問題が存在し、より優れたAIが成果を上げるための余地が大いにある。この変化は重要な意味を持ち、技術進歩が複利的に進むからこそ、AIがAI研究を加速するという強力な正のフィードバックループも形成される。
別の言い方をすれば、平均的なユーザーの質問に対する回答精度の向上余地は限られているが、技術的進歩を加速させる1%の高度な質問や、現在はモデルが十分に賢くないために聞かれていない質問に対応する可能性の向上には、非常に大きな余地があるということだ。AI研究は、進歩の可能性が大きい分野で改善が進む傾向があり、科学的革新の分野には非常に大きな成果が期待できる。
要約:
Jason Wei氏は、AIの焦点が、一般ユーザー向けの機能の開発から、科学技術の発展を加速させるような高度な機能の開発へとシフトしていくと予測しています。これは、AIがすでに一般的な質問に答えることができるレベルに達しているため、今後はより専門的で複雑な問題解決にAIが活用されるようになるという考えに基づいています。特に、AIが自身の研究を加速させるというポジティブなフィードバックループが生まれ、技術革新が飛躍的に進展すると期待されています。
補足:
- LLM: Large Language Modelの略で、大規模言語モデルのこと。
- 正のフィードバックループ: ある現象が別の現象を引き起こし、それがさらに最初の現象を強化するような連鎖のこと。
以下、海外の反応
- 名無しの外国人
AIが病気を治したり、科学的なブレークスルーを解決し始めたら、人々はもっとAIを愛するようになると思う。ただ、メディアに最初に取り上げられたせいで、少し厳しいスタートを切っただけだ。 - 名無しの外国人
>>1
メディアに最初に登場したのには理由があります。テキスト、画像、ビデオは非常に簡単で、ほとんどの場合、大量のデータと計算力しか必要としません。
一方、病気の治療や科学的ブレークスルーには真の知能が必要です。 - 名無しの外国人
>>2
『病気の治療や科学的ブレークスルーには本当の知性が必要だ』
そうだね、でも科学の分野では、ディープネットワークはまるで膨大な量のデータを処理して隠れたパターンや相関関係、因果関係を見つけられる、無数の“賢くないアシスタント”を持っているようなものなんだ。それがとてつもなく役に立つんだよ。 - 名無しの外国人
>>3
そして、それらの隠れたパターンを何十億ものパラメータの中に隠してしまうんだ。しかもそれを僕たち人間は理解できないんだよ。問題なのは、AIでタスクを解決したとしても(例えばタンパク質の折り畳み問題)、それが必ずしもその問題の理解につながるとは限らないってことだ。もちろん、これらの性質を逆に解析しようとすることはできるから、人間の理解にとって完全に無駄ではないけど、ブラックボックスのAIで最先端の問題を大量に解決できるようになったら、それはちょっと奇妙なことになるだろうね。ひょっとすると、ある問題に対する既存のAIソリューションをさらに進化させる唯一の方法が、AIそのものを改良することだけになるかもしれない。なぜなら、古いソリューションを人間が理解できず、人間からのフィードバックを追加することもできなくなるかもしれないから。 - 名無しの外国人
つまり、特異点です。同時に、彼らはエージェンシーやエージェンシーのための推論などの改善に取り組むべきですが、これは通常のユーザーと科学/エンジニアリングの両方に適用されます。 - 名無しの外国人
>>5
彼らは2025年には、AIエージェントの開発に力を入れており、すでに推論に関する技術を確立しているでしょう。 - 名無しの外国人
それは非常に安全な予測ですね。結局のところ、AIエージェントは一般ユーザーにとってそれほど重要なのでしょうか?それは主に労働者を置き換え、安価に物事を考えるためのものです。 - 名無しの外国人
彼は、現在のLLMはほとんどの質問にうまく答えられると言っていますが、コーディングをしている人のほとんどは、出力に常にエラーを見つけています。
「クエリの上位1%のエクスペリエンスを向上させるための大きな余地がある」というのは、基本的に「私たちのモデルは実際に大幅に改善されましたが、それを利用するにはあなたがあまりにも愚かすぎるのです」という言い訳です。 - 名無しの外国人
>>8
私はそれが真実であると確信しています。あなたが専門家ではないトピックについてAIに質問すると、ほとんどの場合、正しい答えが返ってきますが、それが本当に正しいのか間違っているのかを評価する方法がわかりません。
これがLLMsのリーダーボードが役に立たない理由です。 - 名無しの外国人
>>9
LLMsのベンチマークは冗談です。より良いベンチマークはSimpleBenchで、現在は最良のAIシステムでも平均的な人間の半分ほどの知能しかないことを示しています。基本的に、現在のAIは、IQが約50の非常に教育を受けた人と同じです。 - 名無しの外国人
>>10
本当にGPT-4oミニはクロード・オーパスより良くないんですか? - 名無しの外国人
>>11
そうだね、YouTuberが作ったようなトリッキーな質問を集めるのが、知能を測る最適な方法だと考える人がいるんだろうね。しかもIQが線形スケールだと思ってる人にとってはね。
『IQが50の人って、IQが100の人の半分くらい賢いってことだよね、みんな?』――IQ25の誰か - 名無しの外国人
安っぽい話だ。OpenAIは、「AGI 」という漠然とした約束だけでなく、実際にそれを証明する必要がある。
一方、アルファフォールドはタンパク質の折り畳みを解明し、ノーベル賞を受賞した。 - 名無しの外国人
>>13
o1は、モデルに効果的な推論を与え、無限に供給される合成データで推論を向上させるよう効果的に訓練し、潜在的な収穫の減少を回避した。彼らは今、モデルに主体性を与えることに集中している。これが科学的進歩への道でないとしたら、何がそうなのか私にはわからない。 - 名無しの外国人
>>13
これは未来に対する予測です。ChatGPTは明らかに、エンジニアを含むさまざまな分野の人々の生産性向上に貢献しており、ベンチマークの結果も、STEM(科学、技術、工学、数学)分野でますます能力を高めていることを示しています。66億ドルかそれ以上投資した投資家たちは、きっと十分な調査を行ったことでしょう。 - 名無しの外国人
LLMは非常に急速に発展していますが、現時点では、研究面での進展はあまり見られません。
彼らは、加速的な技術的ブレークスルーを実現するために、これまで生きてきた最も賢い人間と同等かそれ以上の知能を持ち、かつ自律的に何時間も働けるものを構築する必要があります。 - 名無しの外国人
>>16
人間と同じくらい賢くなくても構いません。人間よりもはるかに速く、無限に働くことができ、同時に無制限のコピーが働くことができます。これと、インターネット全体以上の完璧な記憶を組み合わせれば、非常に効果的な研究者になります。特に優れた研究である必要はなく、最初は量より質ですが、それでも多くの潜在的なブレークスルーが得られるでしょう。 - 名無しの外国人
>>17
しかし、多くの分野の研究はノートブック上で行われるわけではありません。世界を理解したいなら、仮説検証をしなければなりません。これがすでに限界要因です。素粒子物理学で新しいアイデアを思いついた?残念ですが、それをテストするにはさらに大きな粒子加速器を建設する必要があります。病気を治すための潜在的な新薬がある?さて、まずそれを実行するためのヒト試験を設定しましょう。
AIが世界と相互作用することなく、単独で科学のすべてを解明できると考えるのは非常にナイーブです。AIはこれまで私たちが収集したデータに依存しています。まだ解明されていないものが隠れているかもしれませんが、私たちが持っているものから学べることには明らかに限界があります。AlphaFoldが機能した理由は、人間がそのための優れたデータを持っていたからです。しかし、科学のあらゆる問題に当てはまるでしょうか?
本当に科学をやりたいなら、AIにすべてをやらせる必要があります。仮説と実験を考え出し、実験を実行して評価し、仮説を調整して繰り返します。そして、これは非常に複雑なシステムとロボット工学を必要としますが、残念ながらロボット工学は一般的なユーザビリティに関してLLMにすら遠く及びません。そして、現実世界に足を踏み入れると、AIは私たちと同じ物理法則に従う必要があります。現実世界では物事は時間がかかり、AIは一夜にして次の大型粒子加速器を設計・建設するわけではありません
数学とコンピュータサイエンスはこの点でより簡単かもしれませんが、AIがこれらの分野で画期的な成果を挙げられるかどうか見てみましょう。 - 名無しの外国人
>>18
最初は仮説ジェネレーターになりますが、それでも研究を大幅に加速させるでしょう。さらに、研究する最も重要なものはすべてコンピューター内にあるので、自由に行動できます。ソフトウェアをテストするためにロボットは必要ありません。そして、もはや私たちのデータに依存するのではなく、合成データで訓練されます。
それは信じられないほど速くアイデアを生成し、アイデアを良し悪しで分類し、良いアイデアの思考プロセスはモデルをさらに賢くし、より良いアイデアを生み出します。1か月後には、少なくとも1つの潜在的なブレークスルーがあることはほぼ確実です。そのようなアイデアは簡単に見つかるものではありませんが、超人的な記憶を持つ多数の知能から、途方もない量のアイデアが得られれば、はるかに簡単になります。
また、「科学のすべてを解明する」と言わないでください。それは決して目標ではないことはすでに明確に述べています。 - 名無しの外国人
私は彼が概ね正しいと思いますが、Google DeepMindも長い間この分野に注目しており、この追求において他のプレイヤーを凌駕する準備ができていると思います。 - 名無しの外国人
AI業界では最近、多くの転換が見られます。これは、スケーリングが限界に達しつつあることを示しているのかもしれません。 - 名無しの外国人
アイデアはたくさんあるのに、それを試すための余分なFLOPS(浮動小数点演算能力)が足りないのに、どうしてAIがAI研究を加速させるのか理解できません。 - 名無しの外国人
ASI達成には不可欠なステップだ
redditの『
OpenAIのJason Weiは、「予測:今後1年以内に、AIの焦点が一般的なユーザーの採用から科学技術の加速化へとかなり急激に移行するだろう」』より
翻訳元


コメント